Our 10-point technical debt assessment
In the six years since we first introduced radically simple metrics for code quality, we’ve found that clear, actionable metrics leads to better code and more productive teams. To further that, we recently revamped the way we measure and track quality to provide a new, clearer way to understand your projects.

Our new rating system is built on two pillars: maintainability (the opposite of technical debt) and test coverage. For test coverage, the calculations are simple. We take the covered lines of code compared to the total “coverable” lines of code as a percentage, and map it to a letter grade from A to F.
Technical debt, on the other hand, can be a challenge to measure. Static analysis can examine a codebase for potential structural issues, but different tools tend to focus on different (and often overlapping) problems. There has never been a single standard, and so we set out to create one.
Our goals for a standardized technical debt assessment were:
Cross-language applicability - A good standard should not feel strained when applied to a variety of languages, from Java to Python to JavaScript. Polyglot systems are the new normal and engineers and organizations today tend to work in an increasing number of programming languages. While most languages are based on primitive concepts like sequence, selection, and iteration, different paradigms for organizing code like functional programming and OOP are common. Fortunately, most programming languages break down into similar primitives (e.g. files, functions, conditionals).
Easy to understand - Ultimately the goal of assessing technical debt with static analysis is to empower engineers to make better decisions. Therefore, the value of an assessment is proportional to the ease with which an engineer can make use of the data. While sophisticated algorithms may provide a seemingly appealing “precision”, we’ve found in our years of helping teams improve their code quality that simple, actionable metrics have a higher impact.
Customizable - Naturally, different engineers and teams have differing preferences for how they structure and organize their code. A good technical debt assessment should allow them to tune the algorithms to support those preferences, without having to start from scratch. The algorithms remain the same but the thresholds can be adjusted.
DRY (Don’t Repeat Yourself) - Certain static analysis checks produce highly correlated results. For example, the cyclomatic complexity of a function is heavily influenced by nested conditional logic. We sought to avoid a system of checks where a violation of one check was likely to be regularly accompanied by the violation of another. A single issue is all that’s needed to encourage the developer to take another look.
Balanced (or opposing) - Tracking metrics that encourage only one behavior can create an undesirable overcorrection (sometimes thought of as “gaming the metric”). If all we looked for was the presence of copy and pasted code, it could encourage engineers to create unwanted complexity in the form of clever tricks to avoid repeating even simple structures. By pairing an opposing metric (like a check for complexity), the challenge increases to creating an elegant solution that meets standard for both DRYness and simplicity.
Ten technical debt checks
With these goals in mind, we ended up with ten technical debt checks to assess the maintainability of a file (or, when aggregated, an entire codebase):
Argument count - Methods or functions defined with a high number of arguments
Complex boolean logic - Boolean logic that may be hard to understand
File length - Excessive lines of code within a single file
Identical blocks of code - Duplicate code which is syntactically identical (but may be formatted differently)
Method count - Classes defined with a high number of functions or methods
Method length - Excessive lines of code within a single function or method
Nested control flow - Deeply nested control structures like if or case
Return statements - Functions or methods with a high number of return statements
Similar blocks of code - Duplicate code which is not identical but shares the same structure (e.g. variable names may differ)
Method complexity - Functions or methods that may be hard to understand
Check types
The ten checks break down into four main categories. Let’s take a look at each of them.
Size
Four of the checks simply look for the size or count of a unit within the codebase: method length, file length, argument count and method count. Method length and file length are simple enough. While these are the most basic form of static analysis (not even requiring parsing the code into an abstract syntax tree), most programmers will identify a number of times dealing with the sheer size of a unit of code has presented challenges. Refactoring a method that won’t fit all on one screen is a herculean task.
The argument count check is a bit different in that it tends to pick up data clumps and primitive obsession. Often the solution is to introduce a new abstraction in the system to group together bits of data that tend to be flowing through the system together, imbuing the code with additional semantic meaning.
Control flow
The return statements and nested control flow checks are intended to help catch pieces of code that may be reasonably sized but are hard to follow. A compiler is able to handle these situations with ease, but when a human tasked with maintaining a piece of code is trying to evaluate control flow paths in their head, they are not so lucky.
Complexity
The complex boolean logic check looks for conditionals laced together with many operators, creating an exploding set of permutations that must be considered. The method complexity check is a bit of a hybrid. It applies the cognitive complexity algorithm which combines information about the size, control flow and complexity of a functional unit to attempt to estimate how difficult a unit of code would be to a human engineer to fully understand.
Copy/paste detection
Finally, the similar and identical blocks of code checks look for the especially nefarious case of copy and pasted code. This can be difficult to spot during code review, because the copied code will not show up in the diff, only the pasted portion. Fortunately, this is just the kind of analysis that computers are good at performing. Our copy/paste detection algorithms look for similarities between syntax tree structures and can even catch when a block of code was copied and then a variable was renamed within it.
Rating system
Once we’ve identified all of the violations (or issues) of technical debt within a block of code, we do a little more work to make the results as easy to understand as possible.
File ratings
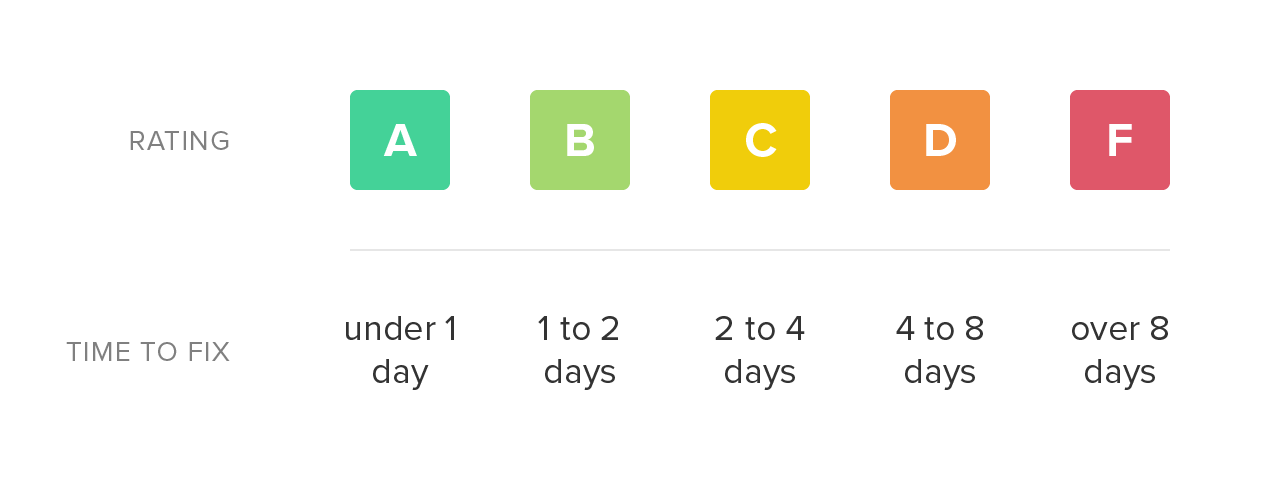
First, for each issue, we estimate the amount of time it may take an engineer to resolve the problem. We call this remediation time, and while it’s not very precise, it allows us to compare issues to one another and aggregate them together.
Once we have the total remediation time for a source code file, we simply map it onto a letter grade scale. Low remediation time is preferable and receives a higher rating. As the total remediation time of a file increases, it becomes a more daunting task to refactor and the rating declines accordingly.
Repository ratings
Last, we created a system for grading the technical debt of an entire project. In doing so, we’re cognizant of the fact that older, larger codebases naturally will contain a higher amount of technical debt in absolute terms compared to their smaller counterparts. Therefore, we estimate the total implementation time (in person-months) of a codebase, based on total lines of code (LOC) in the project, and compute a technical debt ratio: the total technical debt time divided by the total implementation time. This can be expressed as a percentage, with lower values being better.

We finally map the technical debt ratio onto an A to F rating system, and presto, we can now compare the technical debt of projects against one another, giving us an early warning system when a project starts to go off course.
Get a free technical debt assessment for your own codebase
If you’re interested in trying out our 10-point technical debt assessments on your codebase, give Code Climate a try. It’s always free for open source, and we have a 14-day free trial for use with private projects. In about five minutes, you’ll be able to see just how your codebase stacks up. We support JavaScript, Ruby, PHP, Python and Java.
If you’re already a Code Climate customer, you can expect a rollout of the new maintainability and test coverage ratings over the next few weeks – but if you’d like them sooner, feel free to drop us a line, we’re always happy to help!